Emerging Architectures and Pipelines of Quantum Compilers
Quantum Compiler Architectures Are Evolving

Preface
Quantum computing has matured to the point where a recognizable compilation pipeline has begun to emerge across many software frameworks and hardware platforms. Circuit optimization is often treated as the central open challenge in quantum compilation since near-term quantum devices remain constrained by limited native gate sets, sparse qubit connectivity, short coherence times, and significant noise. However, there is a broader architectural shift now taking place in quantum software.
A major reason for fragmentation among the quantum compiler architecture is the diversity of hardware available in the current Noisy Intermediate-Scale Quantum (NISQ) era. Each modality imposes different constraints, forcing compiler architectures to remain highly hardware-aware and platform-specific.
Despite this fragmentation, the most important standards in quantum compilation software can be split into two families.
External Representations
Used to exchange programs between users, SDKs, compilers, hardware vendors, and tools
Internal Compiler Representations
Used inside a compiler or optimization stack to analyze, transform, and lower programs.
Qiskit’s
DAGCircuit
External representations prioritize portability/readability/interoperability. Internal compiler representations prioritize transformation/optimization. For this reason, many quantum software ecosystems maintain multiple representations at once: one for users and interoperability, another for the compiler’s internal reasoning.
Part of any quantum intermediate representation must ultimately be grounded in the circuit model of quantum computation. However, as quantum programs become more dynamic and hybrid, circuit structure alone is no longer sufficient. Modern compiler infrastructures increasingly need to represent classical data alongside quantum information
Moreover, although benchmarking efforts for quantum software toolchains are improving, evaluation methodologies remain fragmented across frameworks, hardware assumptions, and optimization objectives. Initiatives such as IBM Quantum’s Benchpress represent important progress toward more standardized apples-to-apples comparisons, but broader community adoption and more consistent benchmarking practices are still needed. Yet, we still can recognize and understand a quasi-canonical compiler architecture
Quasi-Canonical Compiler Architecture
The common invariant across most modern quantum compilers is that a user program begins in a human-facing language or SDK, is converted into one or more machine-processable internal representations, is rewritten under hardware constraints, and is finally lowered into native instructions, pulse-level descriptions, or a runtime ABI.
User Program
↓
External Representation or SDK Object
↓
Internal Compiler IR
↓
Analysis and Transformation Passes
↓
Hardware-Aware Optimization
↓
Target-Specific Lowering
↓
Executable Instructions, Pulses, or Runtime Calls
Different ecosystems instantiate this pipeline differently.
Qiskit
IBM Quantum’s Qiskit exposes one of the clearest examples of a staged compiler pipeline. A user begins with a QuantumCircuit, which is converted into an internal DAGCircuit representation, then passed through a sequence of compiler passes managed by PassManager
QuantumCircuit → DAGCircuit → passes (PassManager) → output circuit
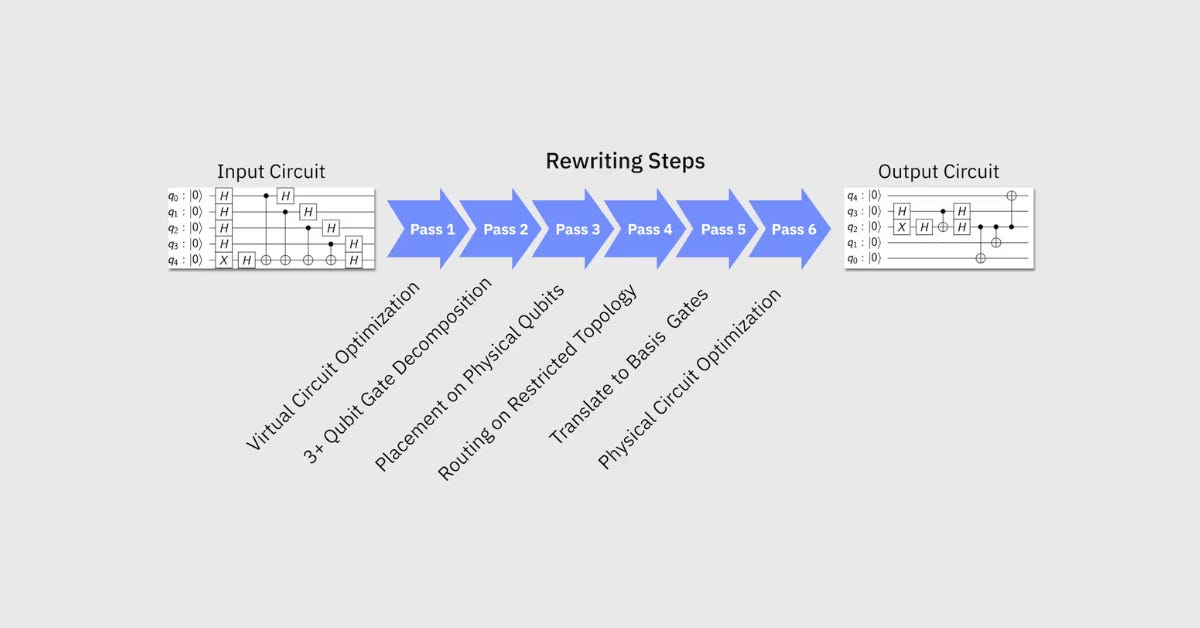
Passes may perform tasks such as circuit decomposition, basis-gate translation, layout selection, routing, optimization, scheduling, etc. Qiskit’s architecture is especially useful pedagogically because it makes many compiler stages explicit.
Cirq
Google Quantum AI’s Cirq follows a broadly similar compilation philosophy. but presents it in a more functional and transformation-oriented style.
cirq.TRANSFORMER = f(Circuit)
Rather than centering the compiler around a single exposed intermediate representation such as Qiskit’s DAGCircuit, Cirq models compile as a sequence of circuit transformations
Circuit → TRANSFORMER → output circuit
We can already see how much compiler infrastructures can differ even among platforms. Yet beneath these differences, we can still begin to recognize the emergent properties of various quantum software ecosystems:
Circuit Model, IR , Optimization/Transformation Passes, Hardware-lowered Output
This is because modern quantum compilers ultimately perform the same fundamental tasks:
Decompose high-level operations into supported gate sets
Rewrite circuits to reduce cost
Map logical qubits onto physical qubits
Route operations under connectivity constraints
Schedule operations under timing constraints
Lower programs onto a target device or execution environment
In this sense, the field appears to be converging toward a shared set of compiler stages and abstractions analogous to the layered infrastructures seen in classical compilation systems.
However, there is a deeper divide hidden among this apparent convergence.
Static vs Dynamic Compilation
A quantum circuit may be mostly or entirely determined before execution begins, or it may be partially modified during execution based on measurement outcomes and classical feedback. The former is usually associated with static compilation. The latter is associated with adaptive, dynamic, or hybrid quantum-classical compilation.
Historically, most quantum software frameworks and compilation pipelines followed the static circuit model. A user or host program generated a quantum circuit, submitted it to a backend, waited for execution, received measurement results, and then performed any further classical processing afterward. This model worked well for many early NISQ-era workloads, especially variational algorithms where a classical optimizer repeatedly generated new circuits between independent quantum executions.
In this static model, classical computation is still essential. However, classical decisions generally occur between circuit executions rather than during a single circuit execution. Dynamic or adaptive execution changes this relationship. In a dynamic model, measurement outcomes can influence later operations while the quantum program is still running, enabling mid-circuit measurement, feed-forward control, adaptive circuit execution, and real-time classical processing.
As quantum computation progresses and begins to transition into early fault-tolerant architectures, classical processing is increasingly becoming a fundamental component of quantum programs. Quantum error correction operations require classical decisions to occur while quantum information remains coherent. Surface-code and qLDPC-based error-correction schemes therefore push compiler and runtime systems toward tighter integration between quantum execution and real-time classical control, requiring more elaborate internal representations than what the static circuit model is able to provide.
The transition from OpenQASM 2.0 to OpenQASM 3.0 provides one of the clearest examples of this broader shift.
OpenQASM 2.0
OpenQASM was originally introduced as a human-readable quantum circuit intermediate representation designed to support near-term experiments with small-depth quantum circuits. Rather than serving as a full hybrid programming language, OpenQASM was initially conceived primarily as a circuit description language.
The original OpenQASM compilation and execution model divided the workflow into several phases: compile time, circuit generation, circuit execution, and post-processing. In this model, a quantum algorithm and classical host program are used to generate one or more quantum circuits. These circuits are then transformed, optimized, submitted to a backend, executed, and measured. Finally, the resulting data is returned to the host program for classical analysis.
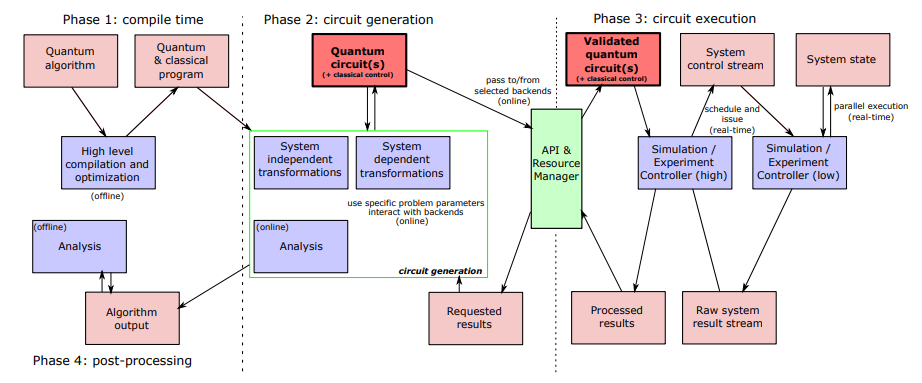
This model is fundamentally oriented around static circuit execution. While classical computation plays a crucial role throughout the process, adaptive classical decisions generally occur between circuit executions rather than during a single circuit’s execution. OpenQASM 2.0 provides only limited support for classical control. It lacks general-purpose constructs such as loops, subroutines, functions, and arbitrary real-time classical computation.
As the field matured, this model became increasingly restrictive. Many important workloads require classical computation to interact more directly with quantum execution. Under the OpenQASM 2.0 model, adaptive decisions are typically made only after a circuit had completed execution and its measurement results had been returned to the host program.
While this execution model was sufficient for many early NISQ-era experiments, it became insufficient as we begin to head towards ETFQC. Tasks such as mid-circuit measurement, feed-forward control, adaptive circuit execution, and quantum error correction require runtime interaction between measurement outcomes and future quantum operations.
These limitations motivated the development of OpenQASM 3.0.
OpenQASM 3.0
OpenQASM 3.0 significantly expands the language, adding new syntax and enhancing the execution model, but its most important contribution is the introduction of language-level support for real-time classical computation and dynamic quantum-classical control.
Recall that a traditional static circuit compiler can often treat a quantum program as a fixed object to be rewritten, optimized, routed, scheduled, and lowered. A dynamic compiler must represent more than a circuit. It must reason about classical state, control flow, timing, measurement dependencies, hardware feedback, and interactions between quantum and classical subsystems. OpenQASM 3.0 adds constructs such as conditionals, loops, subroutines, classical variables, timing controls, external functions, and pulse-level descriptions in order to allow measurement outcomes and classical computations to influence subsequent quantum operations within a single program execution.
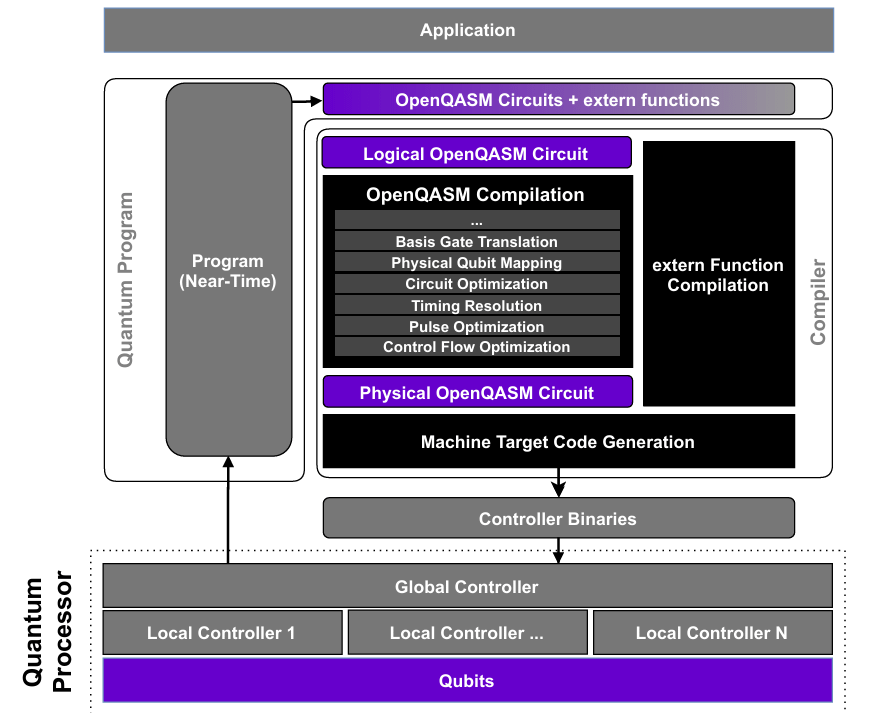
In the OpenQASM 3.0 execution model above, an application is written in terms of a near-term quantum program, and may provide extended quantum circuits and external real-time classical functions to be executed as part of a larger quantum program. These components enter a compilation stack that lowers both the quantum and real-time classical portions into target code suitable for the quantum processor and its control system.
This distinction is often described in terms of near-time and real-time computation.
Near Time Computation
Occurs outside the immediate quantum control loop. It may run on conventional processors and involve arbitrarily complex classical logic, often on timescales ranging from milliseconds to seconds, minutes, or even hours. Examples include variational parameter updates, circuit generation, offline optimization, and post-processing.
Real Time Computation
Occurs inside the quantum control stack while qubits remain coherent. It must often respond on nanosecond or microsecond timescales. Examples include measurement-conditioned operations, feed-forward control, active reset, syndrome decoding, and low-latency corrections.
Static compilation is primarily associated with near-time classical coordination. Dynamic compilation requires real-time classical participation in execution.
By enabling classical computation to participate directly in quantum execution, OpenQASM 3.0 provides a foundation for dynamic circuits and more sophisticated hybrid quantum-classical workflows. More broadly, OpenQASM 3.0 reflects a shift in how quantum programs are represented. It is no longer sufficient for an intermediate representation to describe only a sequence of quantum gates. A modern quantum IR must increasingly describe the relationship between quantum operations, classical computation, timing, control flow, and hardware execution.
In this sense, OpenQASM 3.0 begins to function as a multi-level intermediate representation capable of expressing both logical and physical aspects of quantum computation. This evolution has made the OpenQASM initiative more influential and has also shaped other efforts to build richer hybrid quantum-classical compiler infrastructures.
HUGR
The Hierarchical Unified Graph Representation, or HUGR, is Quantinuum’s approach to a multi-level intermediate representation for hybrid quantum-classical programs. HUGR can be understood as part of the same broad shift that motivates OpenQASM 3.0: quantum programs are no longer adequately represented as static gate sequences alone.
Traditional DAG-based circuit representations work well when programs are mostly static and quantum operations dominate the representation. In a conventional quantum circuit DAG, nodes represent operations and edges represent dependencies between them. This structure is well suited for many standard compiler tasks, such as gate cancellation, commutation analysis, routing, and scheduling.
However, once control flow, classical computation, and nested program structure become first-class concerns, traditional DAG representations become strained. Hybrid quantum-classical programs may contain conditionals, loops, function calls, measurement-dependent branches, and classical values that are copied and reused across multiple operations. A representation designed primarily around linear quantum dataflow is not always expressive enough for these programs.
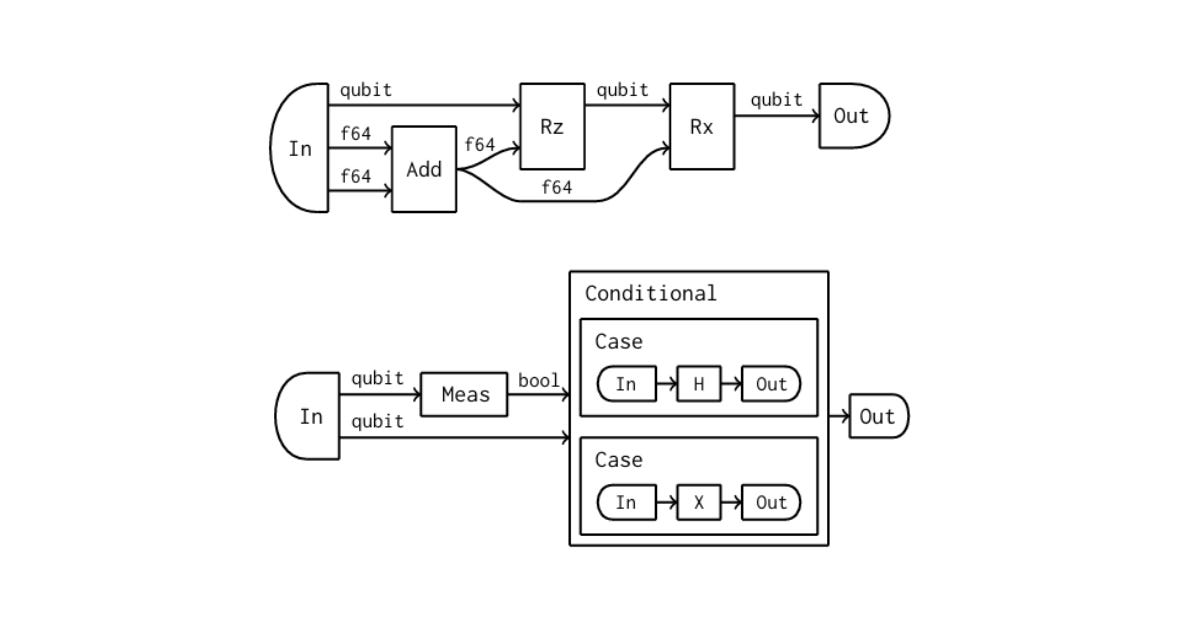
HUGR addresses this problem by representing computation as a graph of operations connected by typed edges. Like traditional circuit DAGs, it captures dependencies between operations. Unlike conventional circuit representations, HUGR allows edges to carry both quantum and classical data.
This distinction matters because quantum and classical data obey different structural rules. Classical values may generally be copied, reused, and consumed by multiple operations. Qubits, by contrast, must be treated as linear types: they cannot be freely copied or duplicated because of the no-cloning theorem and the physical constraints of quantum information. HUGR’s type structure allows these different forms of dataflow to coexist within a single representation.
HUGR also introduces hierarchy. Rather than representing all operations in one flat graph, it allows nested graph structures, making it possible to represent conditionals, loops, function definitions, and other control-flow constructs as subgraphs inside the larger program representation.
Future quantum compilers will need to reason across multiple abstraction levels. They will need to optimize logical circuits, preserve high-level control flow where useful, lower operations to hardware-specific gates, account for timing constraints, interface with classical runtime systems, and eventually support fault-tolerant execution. Representations such as HUGR suggest that the field is moving away from purely circuit-shaped IRs and toward richer program-shaped IRs.
Open Problems
The reviewed literature and platform documentation point to several recurring open problems in quantum compiler architecture.
Portable Multi-Level IRs Remain Incomplete
A truly portable, multi-level quantum IR remains incomplete. OpenQASM 3.0, QIR, and HUGR are among the strongest public foundations, but none currently provides a universally adopted path from high-level hybrid quantum programs all the way down to native controller behavior across superconducting, trapped-ion, neutral-atom, photonic, and other modalities.
Benchmarking Remains Fragmented
Benchmarking is still inconsistent across tools and modalities. Benchpress is a major step toward standardized comparison, but the public benchmark landscape is unable to provide a single canonical suite covering all major compilers, all IR families, and all relevant hardware topologies under identical assumptions.
One compiler may optimize for two-qubit gate count, another for T-count, another for circuit depth, another for estimated fidelity, and another for hardware runtime. Without shared benchmark suites and cost models, claims about compiler performance remain difficult to compare.
Adaptive Compilation Is Maturing Faster Than Its Theory
OpenQASM 3.0, QIR adaptive profiles, Q#, Catalyst, and HUGR all point toward richer hybrid control. However, the theory and benchmarking infrastructure for adaptive quantum compilation remain less mature than the engineering.
Static circuits are relatively easy to compare. Dynamic programs are harder. They may contain branches, loops, measurement-conditioned operations, runtime feedback, and interactions with classical control systems. This raises difficult questions about semantics, verification, scheduling, latency, and reproducibility.
Internal Compiler Structures are Unevenly Documented
Public documentation of internal compiler architecture remains uneven across platforms. Some ecosystems, such as Qiskit, expose relatively detailed staged transpiler documentation. Others expose surface-level behavior or language specifications without a detailed public pass-by-pass view of the compiler pipeline.
Compiler transparency affects scientific reproducibility. If researchers cannot inspect or understand the assumptions behind a compiler’s optimization pipeline, it becomes difficult to compare results across systems. Better documentation of internal IRs, pass structures, cost models, and target assumptions would improve both reproducibility and formalization.
Hardware Diversity Continues to Resist Standardization
Quantum hardware diversity is both a strength and a challenge. Superconducting systems, trapped ions, photonics, neutral atoms, and annealing-based devices often imply different computational primitives, timing assumptions, connectivity models, and control requirements.
This makes the dream of a hardware-agnostic compiler stack difficult. Classical computing eventually converged around relatively stable abstractions such as instruction sets, operating systems, and compiler IRs. Quantum computing has not yet reached that level of abstraction stability. The field is still discovering which hardware assumptions should be hidden behind compiler layers and which must remain visible to users and toolchains.
Conclusion
The evolution of quantum compilers over the past decade can be understood as a gradual expansion of what compiler infrastructures are expected to represent.
As quantum computing moves beyond static circuit execution, the demand for richer multi-level intermediate representations continues to grow. Modern compiler infrastructures must represent not only gates and qubits, but also classical data, control flow, timing constraints, hardware characteristics, measurement dependencies, and runtime interaction. In this sense, the compiler is evolving from a circuit optimizer into a system responsible for orchestrating hybrid quantum-classical computation across multiple layers of abstraction.
Whether this evolution ultimately leads to greater standardization or further fragmentation remains an open question. Today, the ecosystem remains divided across languages, SDKs, hardware modalities, benchmark suites, and competing intermediate representations. Yet beneath this diversity, a recognizable pattern is beginning to emerge: layered compiler stacks built around increasingly expressive representations capable of bridging high-level programs and hardware-specific execution.
For that reason, establishing shared standards, interfaces, and benchmarking practices is becoming increasingly important. The standards and architectures that emerge during this transition will shape not only how quantum programs are compiled, but also how future quantum computers are programmed, evaluated, and understood. Much as LLVM helped unify decades of classical compiler research and engineering, the long-term success of quantum software may depend on the community’s ability to develop similarly durable foundations for interoperability and abstraction.
Open Source References

References
1. Qiskit Transpiler Documentation
IBM Quantum. Qiskit Transpiler (qiskit.transpiler). IBM Quantum Documentation. Accessed June 2026. https://quantum.cloud.ibm.com/docs/en/api/qiskit/transpiler
2. OpenQASM 2.0 (arXiv 1707.03429)
Cross, A. W., Bishop, L. S., Smolin, J. A., & Gambetta, J. M. (2017). Open Quantum Assembly Language. arXiv:1707.03429 [quant-ph]. https://arxiv.org/abs/1707.03429
3. OpenQASM 3.0 (arXiv 2104.14722)
Cross, A. W., Javadi-Abhari, A., Alexander, T., de Beaudrap, N., Bishop, L. S., Heidel, S., Ryan, C. A., Sivarajah, P., Smolin, J., Gambetta, J. M., & Johnson, B. R. (2022). OpenQASM 3: A broader and deeper quantum assembly language. ACM Transactions on Quantum Computing, 3(3). arXiv:2104.14722. https://arxiv.org/abs/2104.14722
4. QWIRE (ACM POPL 2017)
Paykin, J., Rand, R., & Zdancewic, S. (2017). QWIRE: A core language for quantum circuits. Proceedings of the 44th ACM SIGPLAN Symposium on Principles of Programming Languages (POPL ‘17), pp. 846–858. ACM. https://doi.org/10.1145/3093333.3009894
5. Benchpress / Quantum SDK Benchmarking (Nature Computational Science, 2025)
Nation, P. D., Ash Saki, A., Brandhofer, S., Bello, L., Garion, S., Treinish, M., & Javadi-Abhari, A. (2025). Benchmarking the performance of quantum computing software for quantum circuit creation, manipulation and compilation. Nature Computational Science, 5, 427–435. https://doi.org/10.1038/s43588-025-00792-y
6. QIR Specification (GitHub)
QIR Alliance. QIR Specification: Defining how to represent quantum programs within the LLVM IR.* GitHub repository, qir-alliance/qir-spec. Accessed June 2026. https://github.com/qir-alliance/qir-spec/blob/main/specification/README.md
7. Blackbird (GitHub / Xanadu)
Xanadu AI. Blackbird: A quantum assembly language for continuous-variable quantum computation. GitHub repository, `XanaduAI/blackbird`. Accessed June 2026. https://github.com/XanaduAI/blackbird
8. Cirq Circuit Transformers (Google Quantum AI)
Google Quantum AI. Circuit Transformers. Cirq Documentation. Accessed June 2026. https://quantumai.google/cirq/transform/transformers
9. TKET / pytket Circuit Construction (Quantinuum)
Quantinuum. Circuit Construction. pytket User Guide. Accessed June 2026. https://docs.quantinuum.com/tket/user-guide/manual/manual_circuit.html
10. PennyLane Catalyst Architecture
Xanadu AI. Architecture. Catalyst Documentation (v0.15.0). PennyLane. Accessed June 2026. https://docs.pennylane.ai/projects/catalyst/en/stable/dev/architecture.html
11. ProjectQ (arXiv 1612.08091)
Steiger, D. S., Häner, T., & Troyer, M. (2018). ProjectQ: An open source software framework for quantum computing. Quantum, 2, 49. https://doi.org/10.22331/q-2018-01-31-49. arXiv:1612.08091.